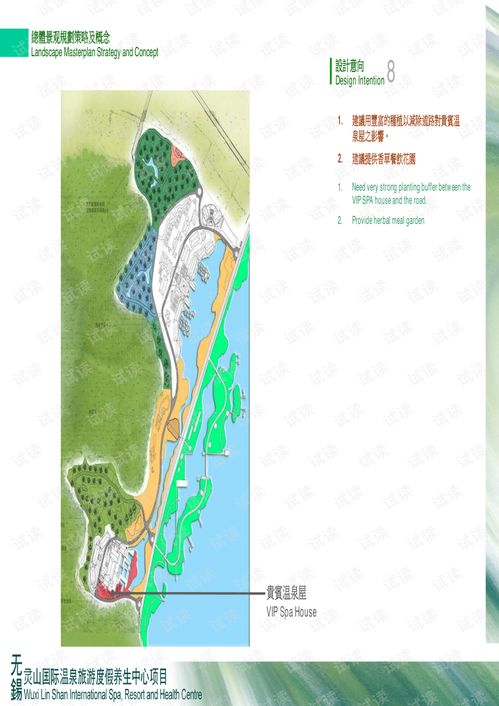
2023年全球及中國淋浴房行業洞察與旅游開發項目策劃咨詢融合新思路
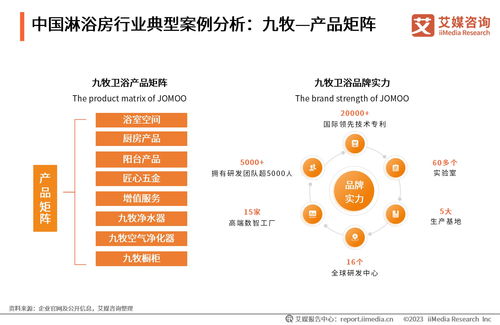
在消費升級與健康生活理念普及的背景下,淋浴房行業作為家居衛浴空間升級的核心載體,正經歷著深刻變革。與此旅游開發項目,特別是高端酒店、度假村及康養文旅項目,對高品質、個性化衛浴空間的需求日益凸顯。本文將結合艾媒咨詢《2023年全球及中國淋浴房行業發展白皮書》的核心洞察,探討淋浴房行業發展趨勢如何為旅游開發項目策劃咨詢注入新的思路與價值。
一、 行業白皮書核心洞察:趨勢與機遇
艾媒咨詢的白皮書揭示了2023年淋浴房行業的幾大關鍵趨勢:
- 市場持續增長:全球范圍內,尤其是中國市場,隨著精裝修房滲透率提升和存量房翻新需求釋放,淋浴房市場保持穩健增長。智能化、個性化、健康化成為產品升級的主要方向。
- 產品技術革新:從簡單的干濕分離到智能恒溫、氛圍燈光、音樂娛樂、健康監測等一體化解決方案,淋浴房正從功能性產品向體驗式、享受型空間轉變。抗菌玻璃、自清潔涂層等健康材料備受關注。
- 設計美學升級:極簡無框設計、多元化材質搭配(如玻璃、石材、金屬)、定制化尺寸與顏色,使得淋浴房更能融入整體衛浴設計,提升空間美學價值。
- 綠色環保導向:節水技術、環保可回收材料的使用,符合全球可持續發展的主流趨勢,也成為高端項目的重要遴選標準。
二、 旅游開發項目策劃咨詢的融合應用策略
基于以上行業趨勢,旅游開發項目(如高端度假酒店、溫泉康養中心、精品民宿集群、郵輪及房車營地等)在策劃與設計階段,可深度融合淋浴房的最新理念,打造差異化競爭優勢:
- 策劃定位與主題融合:
- 康養旅游項目:重點整合具有健康監測(如心率、體重)、芳香療愈、水療按摩功能的智能淋浴房,將其作為核心康養體驗環節進行策劃。
- 生態度假項目:優先選用采用節水技術和環保材料的淋浴房產品,并將自然景觀(如山林、星空)通過無框或大面積玻璃設計引入淋浴空間,實現“沐浴于自然”的獨特賣點。
- 城市精品酒店:強調設計感與個性化,采用定制化、藝術化的淋浴房設計,將其作為客房內的亮點空間進行宣傳,吸引追求設計美學和獨特體驗的客群。
- 空間設計與體驗升級:
- 在項目客房及公共衛浴空間設計中,超越傳統的“干濕分離”基礎需求,策劃“淋浴體驗區”。通過空間布局、燈光、聲音、香氛與智能淋浴設備的聯動,打造沉浸式的感官體驗。
- 針對家庭游客、情侶游客等不同客群,可策劃設計雙人淋浴空間、親子安全淋浴空間等差異化產品。
- 供應鏈整合與成本優化:
- 在項目咨詢的供應鏈管理環節,建議與具備強大研發和定制能力的頭部淋浴房品牌建立戰略合作。針對項目整體風格和大量采購需求,進行聯合設計與集中采購,在保證品質與設計統一性的同時優化成本。
- 考慮引入具有長壽命、低維護特性的產品,降低項目長期運營的維護成本。
- 營銷與品牌價值提升:
- 將“高端智能淋浴體驗”、“環保健康沐浴空間”等作為項目宣傳的具體亮點,在營銷材料中予以視覺和文案上的突出展示,提升項目整體品質感和價值感。
- 可與淋浴房品牌開展跨界營銷合作,如推出聯名主題套房,共同舉辦體驗活動,實現品牌共贏。
三、 結論與建議
《2023年全球及中國淋浴房行業發展白皮書》所揭示的趨勢,不僅為制造企業指明了方向,也為下游應用端——特別是對體驗感要求極高的旅游開發項目——提供了寶貴的升級思路。在旅游項目策劃咨詢中,主動納入前沿的衛浴空間解決方案,是從細節處提升項目競爭力、創造獨特客戶價值的關鍵。
建議旅游項目投資方與策劃咨詢機構,在項目前期就將衛浴空間的創新設計作為重要議題,進行專項規劃和資源對接,從而在日益激烈的市場競爭中,打造出真正打動人心、難以復制的沉浸式旅居體驗。
如若轉載,請注明出處:http://www.lgmould.cn/product/72.html
更新時間:2026-06-19 19:44:09